
The big picture: Google has developed three AI compression algorithms – TurboQuant, PolarQuant, and Quantized Johnson-Lindenstrauss – designed to significantly reduce the memory footprint of large language models without degrading performance or output quality. All three use vector quantization, a data optimization technique that could help AI companies reduce hardware costs as memory prices reach record highs.
The biggest memory burden for LLMs is the key-value cache, which stores conversational context as users interact with AI chatbots. The cache grows as conversations lengthen, increasing both memory usage and power consumption. TurboQuant addresses this issue by reducing model size with "zero accuracy loss," improving vector search efficiency, and alleviating key-value cache bottlenecks.
It achieves this by using PolarQuant, a high-compression method that randomly rotates data vectors to simplify their geometry, making it easier to apply a standard, high-quality quantizer to map large datasets of continuous values. If it performs as advertised, it could significantly boost on-device AI processing on consumer smartphones and laptops by enabling them to retain more context and support longer chatbot conversations.
To minimize errors in the output, TurboQuant uses 1 bit of compression to apply the Quantized Johnson-Lindenstrauss algorithm, which acts as a mathematical error-correction mechanism, reducing bias and improving accuracy. The algorithm employs a specialized estimator that balances high-precision queries with low-precision, simplified data to calculate the "attention score," which determines which parts of the input are most relevant and which can be ignored.
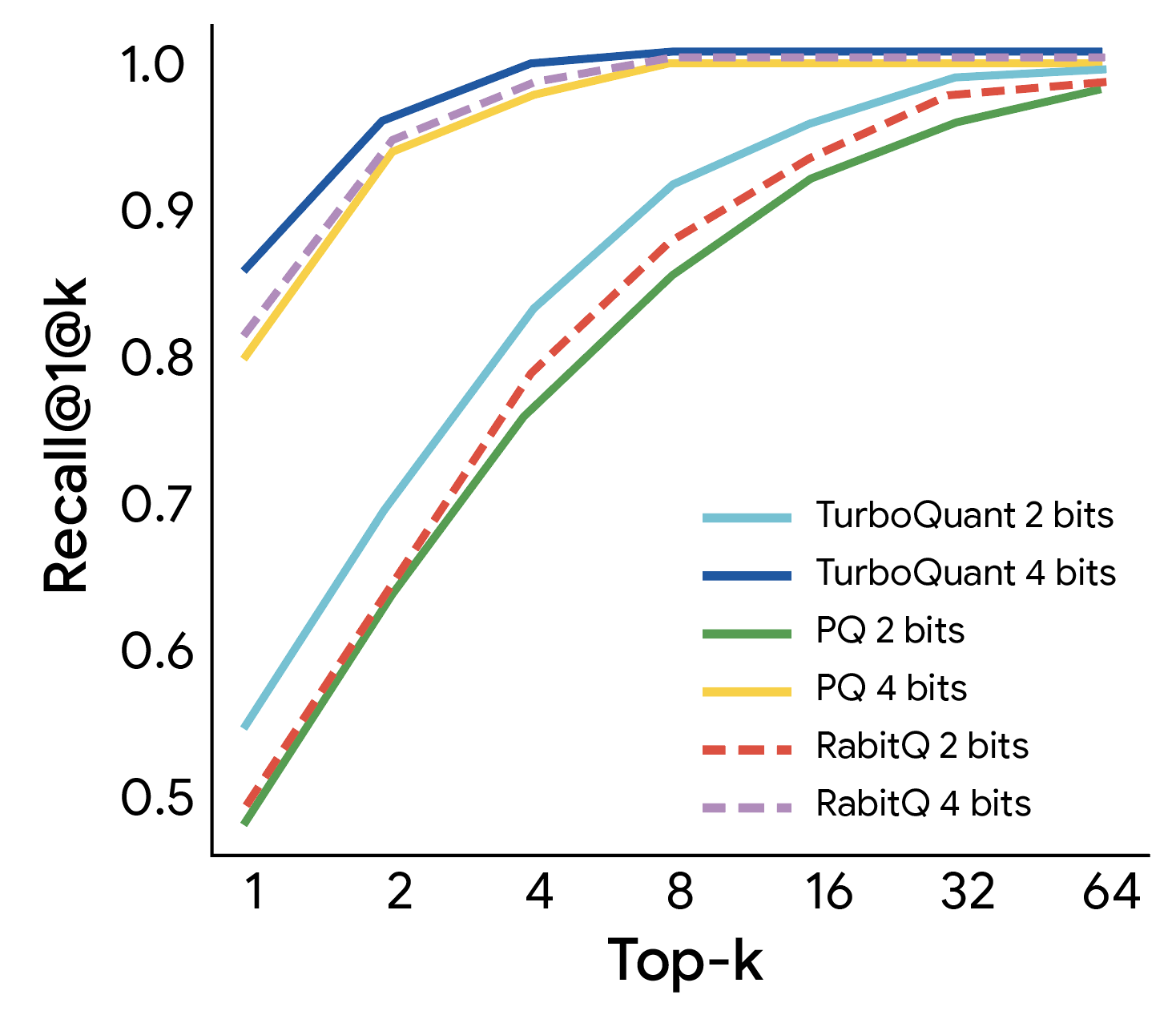
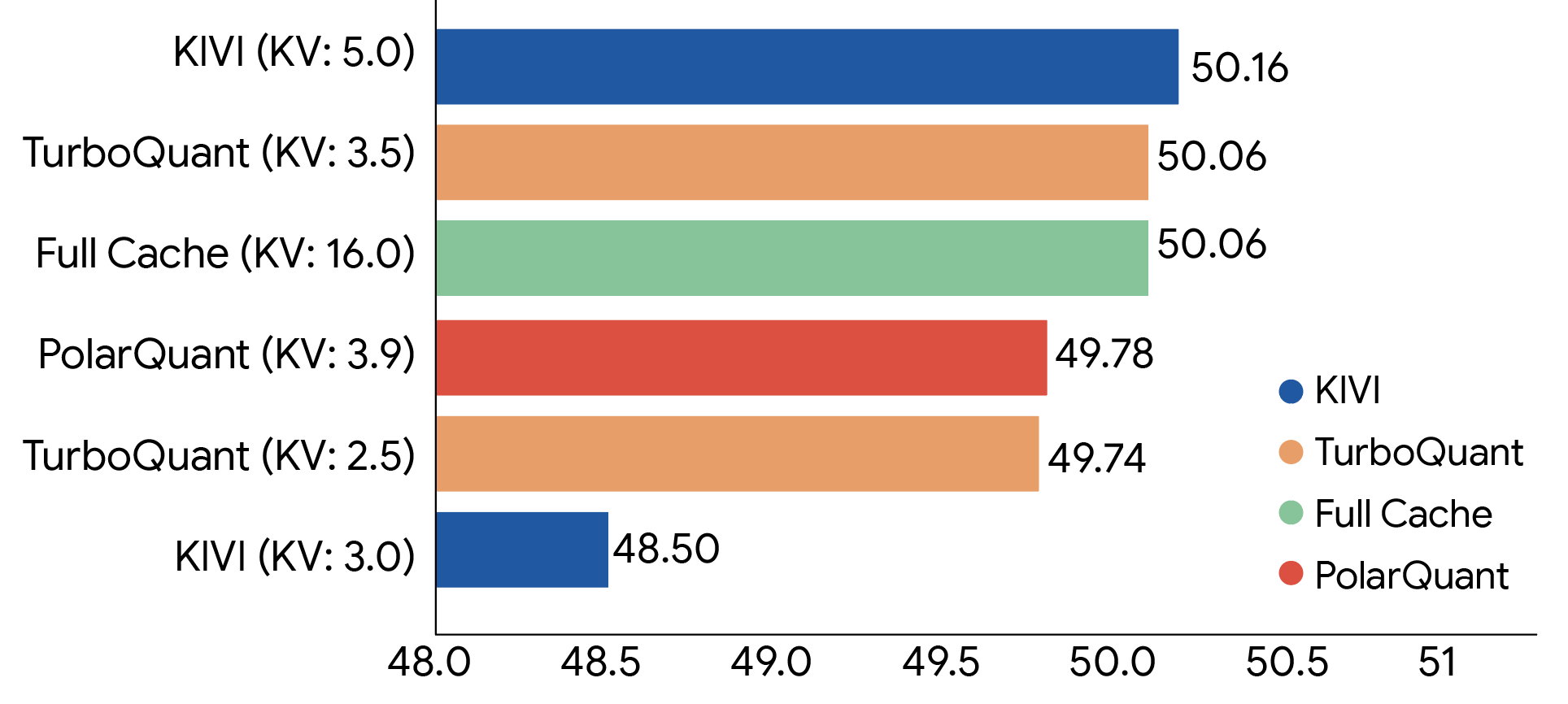
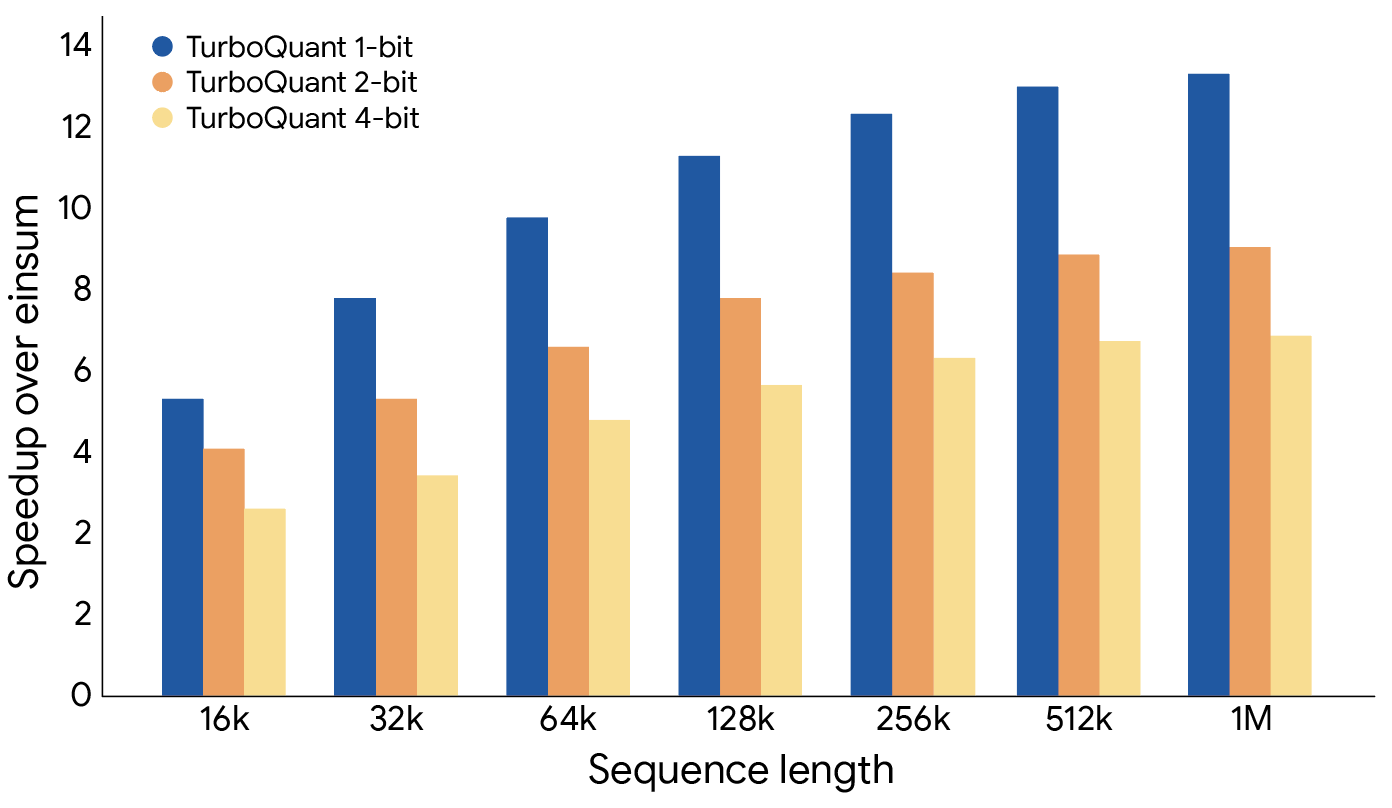
Google evaluated all three algorithms across a range of standard long-context benchmarks, including LongBench, Needle in a Haystack, ZeroSCROLLS, RULER, and L-Eval, using the open-source Gemma and Mistral LLMs. The results show that TurboQuant achieves strong performance in both dot product distortion and recall while reducing the key-value memory footprint by at least 6×.
Google's AI engineers believe the new algorithms can not only reduce the voracious memory demands of multimodal LLMs like Gemini, but also deliver the efficiency and accuracy required for mission-critical applications. However, the benefits of efficient online vector quantization extend beyond addressing the key-value cache bottleneck, enabling improved web search results with minimal memory usage, near-zero latency, and high accuracy.
The new AI algorithms offer a ray of hope for the global consumer electronics industry, which has seen input costs rise sharply in recent months due to the AI boom, a trend that has triggered a global memory shortage and pushed DRAM prices to record highs. If TurboQuant delivers on its promise, it could reduce the high-bandwidth memory requirements for AI data centers, potentially helping stabilize consumer electronics prices in the near future.